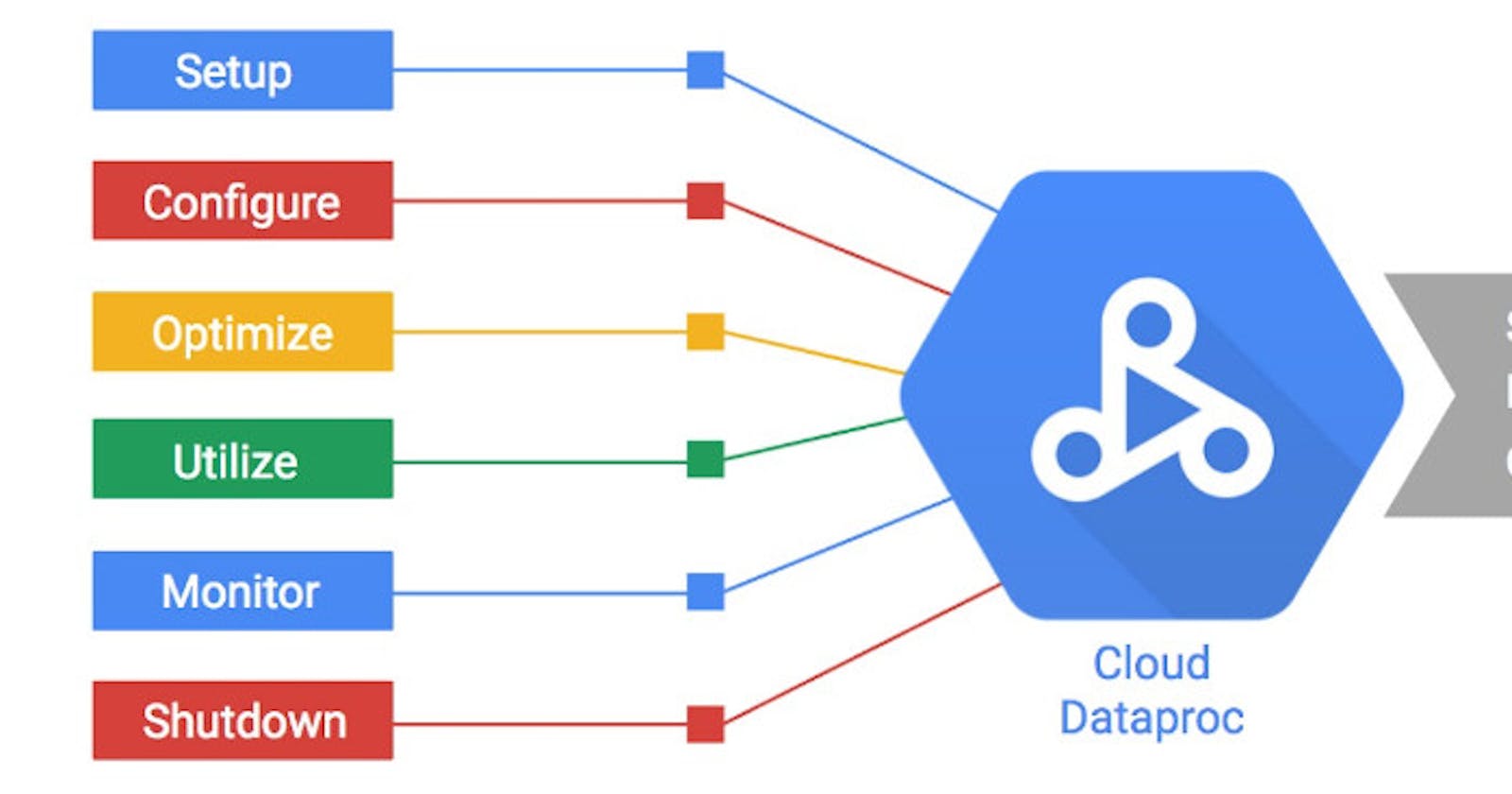


Introduction
Google Dataproc is a fast and easy-to-use, fully managed cloud service for running Apache Spark and Hadoop workloads. It allows users to process and analyze large-scale data efficiently and at scale. Key features and benefits of Google Dataproc include:
Fast and Scalable Processing: Dataproc enables users to run Apache Spark and Hadoop workloads on Google Cloud Platform, taking advantage of its scalable infrastructure and resources.
Integration with Google Cloud Services: Dataproc integrates seamlessly with other Google Cloud services, such as BigQuery, Cloud Storage, and Cloud Spanner, allowing users to access and analyze data in a centralized manner
Data Analytics and Machine Learning: Dataproc supports data scientists and engineers in building and deploying machine learning models, as well as analyzing data using custom-built applications and open-source libraries.
Managed and Secure Environment: Google Dataproc provides a fully managed and secure environment for running data processing workloads, ensuring that users can focus on their data analysis and insights without worrying about infrastructure management.
Overall, Google Dataproc simplifies big data processing and analysis by providing a fast, scalable, and integrated platform for running Apache Spark and Hadoop workloads on Google Cloud Platform.
Use cases
Google Cloud Dataproc has a wide range of use cases for processing large datasets and running big data applications. Here are some of the most popular examples:
Batch processing:
Data warehousing and ETL: Dataproc can be used to extract, transform, and load (ETL) data from various sources into data warehouses like BigQuery. It can also be used to process and clean large datasets for data analysis.
Log processing: Dataproc can be used to analyze massive log files from web applications, servers, and other systems to identify trends and troubleshoot issues.
Financial analysis: Dataproc can be used to analyze large financial datasets for fraud detection, risk assessment, and portfolio management.
Scientific simulations: Dataproc can be used to run large-scale scientific simulations in fields like physics, chemistry, and biology.
Image processing: Dataproc can be used to process and analyze large collections of images and videos for applications like object recognition, facial recognition, and image classification.
Real-time processing:
Data streaming: Dataproc can be used to process data streams in real-time for applications like fraud detection, anomaly detection, and event processing.
Internet of Things (IoT): Dataproc can be used to analyze data from IoT devices in real-time for applications like environmental monitoring, predictive maintenance, and smart city management.
Machine learning: Dataproc can be used to train and deploy machine learning models on large datasets.
Other use cases:
Web scraping: Dataproc can be used to scrape data from websites at scale.
Social media analysis: Dataproc can be used to analyze large social media datasets for sentiment analysis, topic modeling, and social network analysis.
Genomics: Dataproc can be used to analyze large genomic datasets for research and clinical applications.
Pricing
Dataproc on Compute Engine pricing is based on the size of Dataproc clusters and the duration of time that they run. The size of a cluster is based on the aggregate number of virtual CPUs (vCPUs) across the entire cluster, including the master and worker nodes. The duration of a cluster is the length of time between cluster creation and cluster stopping or deletion.
The Dataproc pricing formula is: $0.010 * # of vCPUs * hourly duration.
Although the pricing formula is expressed as an hourly rate, Dataproc is billed by the second, and all Dataproc clusters are billed in one-second clock-time increments, subject to a 1-minute minimum billing. Usage is stated in fractional hours (for example, 30 minutes is expressed as 0.5 hours) in order to apply hourly pricing to second-by-second use.
Dataproc pricing is in addition to the Compute Engine per-instance price for each virtual machine (see Use of other Google Cloud resources).
As an example, consider a cluster (with master and worker nodes) that has the following configuration:
| Item | Machine Type | Virtual CPUs | Attached persistent disk | Number in cluster |
| Master Node | n1-standard-4 | 4 | 500 GB | 1 |
| Worker Nodes | n1-standard-4 | 4 | 500 GB | 5 |
This Dataproc cluster has 24 virtual CPUs, 4 for the master and 20 spread across the workers. For Dataproc billing purposes, the pricing for this cluster would be based on those 24 virtual CPUs and the length of time the cluster ran (assuming no nodes are scaled down or preempted). If the cluster runs for 2 hours, the Dataproc pricing would use the following formula:
Dataproc charge = # of vCPUs * hours * Dataproc price = 24 * 2 * $0.01 = $0.48
In this example, the cluster would also incur charges for Compute Engine and Standard Persistent Disk Provisioned Space in addition to the Dataproc charge (see Use of other Google Cloud resources). The billing calculator can be used to determine separate Google Cloud resource costs.
How to setup a Dataproc cluster
Prerequisites:
Google Cloud Platform Account:
- You need a GCP account. If you don't have one, you can sign up for a free trial at Google Cloud Console.
Enable Billing:
- Make sure you have billing enabled for your GCP project.
Install Google Cloud SDK:
- Install the Google Cloud SDK on your local machine. This SDK includes the
gcloudcommand-line tool, which you'll use to interact with GCP.
- Install the Google Cloud SDK on your local machine. This SDK includes the
Create a GCP Project:
- Create a GCP project if you don't already have one. You can do this through the GCP Console.
Enable APIs:
- Enable the necessary APIs for Dataproc and other services. You can do this through the APIs & Services > Dashboard section in the GCP Console.
Set Up a Dataproc Cluster:
Now that you have the prerequisites in place, you can proceed to set up a Dataproc cluster:
Open Cloud Shell:
Open the Google Cloud Console.
Click on the "Activate Cloud Shell" button in the upper right corner.
Create a Dataproc Cluster:
Use the following
gcloudcommand to create a Dataproc cluster. Adjust the parameters as needed.bashCopy code gcloud dataproc clusters create CLUSTER_NAME \\ --region REGION \\ --num-workers NUM_WORKERS \\ --worker-machine-type MACHINE_TYPE \\ --master-machine-type MASTER_MACHINE_TYPEReplace the placeholders (
CLUSTER_NAME,REGION,NUM_WORKERS,MACHINE_TYPE,MASTER_MACHINE_TYPE) with your desired values.
Access the Cluster:
- Once the cluster is created, you can access the master node using SSH. You can find the SSH command in the Dataproc cluster details in the GCP Console.
Run Jobs:
- Submit jobs to your Dataproc cluster using tools like Apache Spark or Hadoop. You can submit jobs using the
gcloud dataproc jobs submitcommand.
- Submit jobs to your Dataproc cluster using tools like Apache Spark or Hadoop. You can submit jobs using the
Delete the Cluster:
When you're done with the cluster, remember to delete it to avoid incurring unnecessary costs.
bashCopy code gcloud dataproc clusters delete CLUSTER_NAME --region REGIONReplace the placeholders with your cluster's name and region.
How to deploy a Spark job on Dataproc (Using Google cloud console)
Step 1: In the created cluster, click on Submit Job button on the top right of the main console screen

Step 2: Fill in all the necessary fields in the job creation modal:

Job ID: job unique name across the cluster
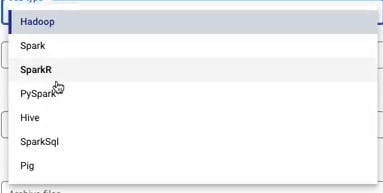
Job Type: the type of job that you submit to Dataproc including (in this demo, we’ll use PySpark):

Main file: the directory of main job file from GCS or HDFS or inside the compute engine.
All others field is optional.
After you fill in the necessary input i should be something like this:
- Then press
Submitto submit the job
Step 3:
After submitting the job you should be able to similar screen to this:

Wait for the job status change to succeeded (or failed):
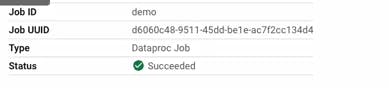
And that is how you run a Spark ( or Hadoop) job on Google Cloud Dataproc.
Conclusion
In conclusion, Google Dataproc stands as a highly efficient and scalable service for handling big data workloads, particularly with its compatibility with Apache Spark and Hadoop ecosystems. The demonstration of setting up a simple PySpark job on this platform highlights Dataproc's strengths in flexibility, speed, and ease of use, even for those new to cloud-based data processing. This practical example underscores how Dataproc simplifies complex data operations, allowing users to focus on extracting valuable insights rather than managing infrastructure. The successful execution of a PySpark job in this environment not only serves as a testament to Google Dataproc’s capabilities but also opens the door for more advanced data processing and analysis endeavors in the cloud.